HDFS 系列: HDFS 架构详解
1 引言
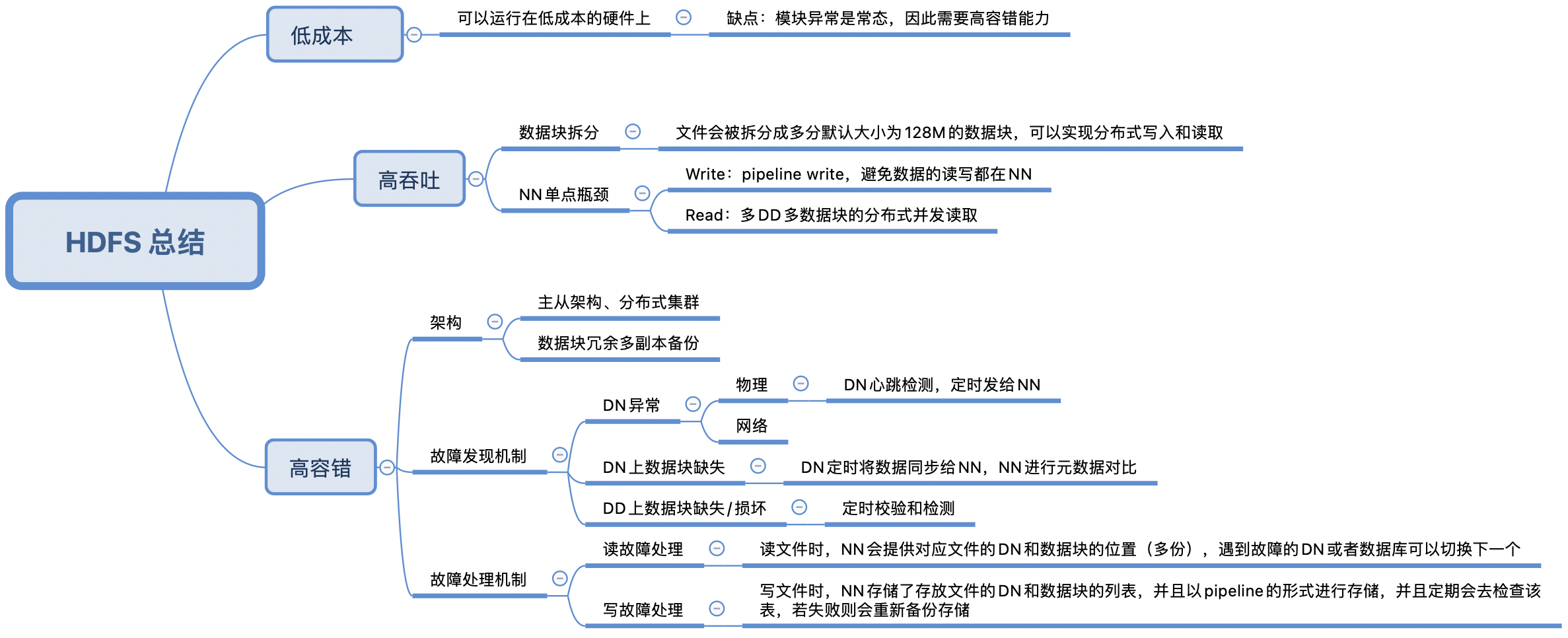
HDFS(Hadoop Distributed File System)是基于 GFS 的思想来实现的可扩展的分布式文件系统,支持海量数据的存储。HDFS 可以运行在低成本的硬件之上,具有高容错、高可靠性、高可拓展性、高吞吐率等特点,非常适合大规模数据集的应用。
2 HDFS 架构图
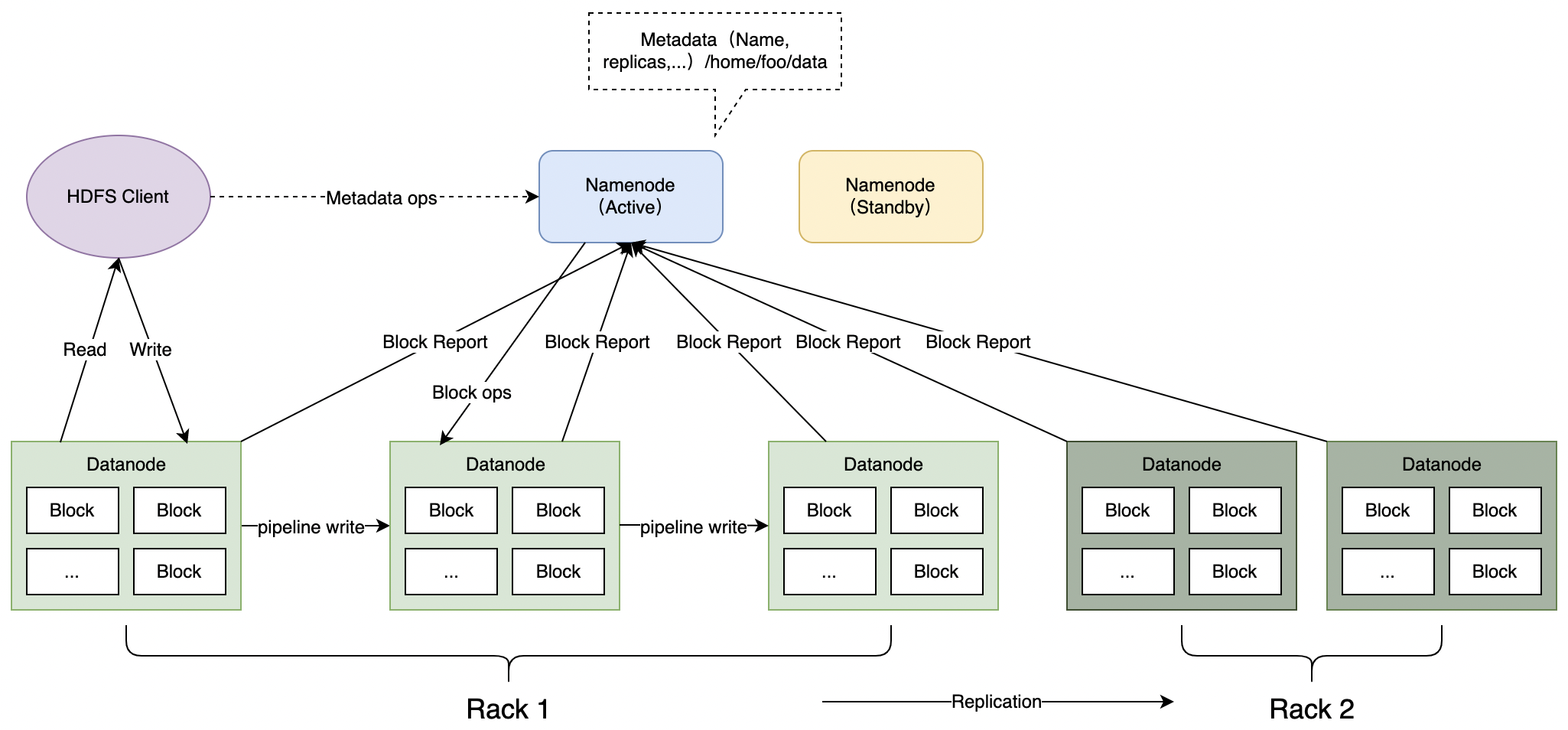
HDFS 是一个主从体系 (Master/Slave) 结构的分布式系统,一个集群由一个 Namenode(NN)和多个 Datanode(DN)组成,用户可以通过 HDFS Client 与 NN 和 DN 交互以访问文件系统。
3 基本概念
3.1 数据块(Block)
HDFS 中文件处理的最小单元(概念可以与 Linux 系统中的 ext2、ext3 相同)。存储在 HDFS 的文件会比较大,为了减少最小化寻址开销,所以 Block 也更大,默认是 128M。Block 一般会以文件的形式存储在 DN 的磁盘上。
在 HDFS 中,为了保证数据的安全性,会将数据块进行冗余备份并保存到不同的 DN 上(一个数据块默认保存 3 份),所以数据块的一个副本丢失也不会影响数据块的访问。
3.2 名字节点(Namenode)
名字节点(Namenode,NN)是 HDFS 主从结构中的主节点(Master)。主要管理文件系统的以下元数据:
- 命名空间
(Namespace) - 文件系统的目录树
- 文件 / 目录信息
- 文件的数据块索引
这些元数据都会在 NN 的本地磁盘上永久保存为两个文件的形式,即:空间镜像文件和编辑日志文件。
NN 还维护数据块与数据节点的映射关系,但是不保存在本地磁盘中,而是在 NN 启动时动态创建的。当 HDFS Client 的请求过来时,会先从 NN 上读取以上信息,再进行文件数据的读写。
可以将 NN 视为一个逻辑上的节点(逻辑上只有单节点,实际上可能不止一个节点)。当 NN 出现故障无法服务时,集群会启用备用 NN,由于 Active NN 的内存元数据与 Standby NN 的数据是完全同步,此时 Standby NN 状态会切换为 Active,不影响集群整体的对外服务。
3.2 数据节点(Datanode)
数据节点(Datanode,DN)是 HDFS 主从结构中的从节点(Slave)。数据存储节点,根据 HDFS Client 的请求或者 NN 的调度,实际执行数据的读取和写入,可以认为是一个物理节点。
DN 作为从节点,会不断地向 NN 发送心跳(Heart Beat)、数据块汇报(Block Report)、缓存汇报(Cache Report)等信息。
3.3 客户端(Client)
HDFS 提供了多种客户端接口:
- 命令行
- 浏览器
- 代码
API
用户可以通过这些接口很方便使用 HDFS。
3.4 通信协议
HDFS 节点间的通信接口主要有两种:
Hadoop RPC:HDFS基于Hadoop RPC框架实现的接口;- 流式接口:
HDFS基于TCP/HTTP实现的接口;
4 主要流程
4.1 读流程
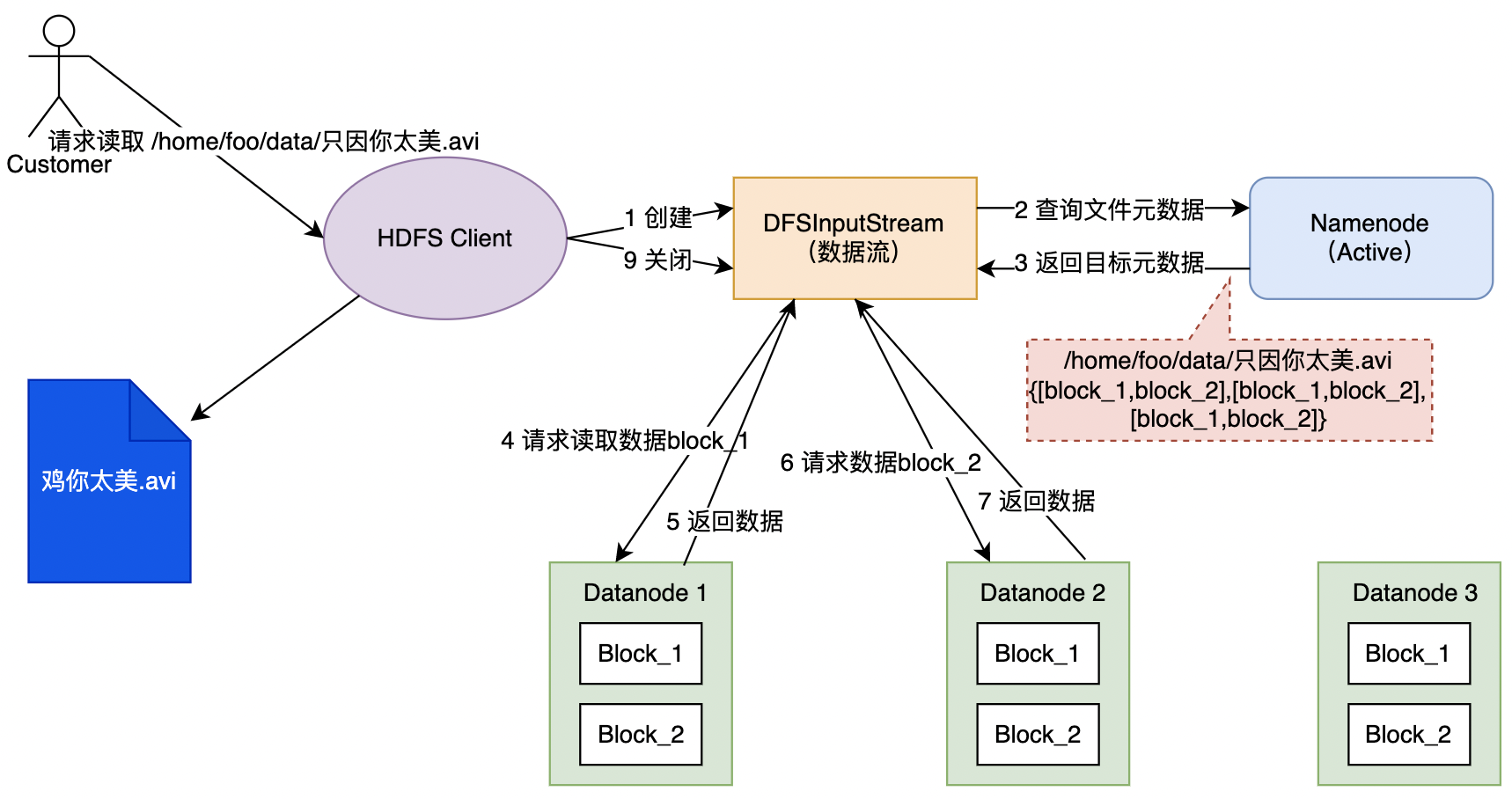
HDFS Client收到用户读请求后,会创建一个数据流对象进行具体的数据读取流程;- 数据流向
NN发送下载文件请求,NN查询目标文件元数据,找到文件所在的DD和对应的数据块Block列表后返回; - 数据流对象会根据文件的元数据,挑选一台多个副本距离较近的
DD,请求读取数据; DD收到读取请求后,开始传输数据给数据流对象(从磁盘阵列读取数据输入流中,切分为多个数据包(Packet)为单位进行校验);Client接受数据,先缓存在本地,待数据流接受完成后,关闭数据流,写入目标文件;
4.2 写流程
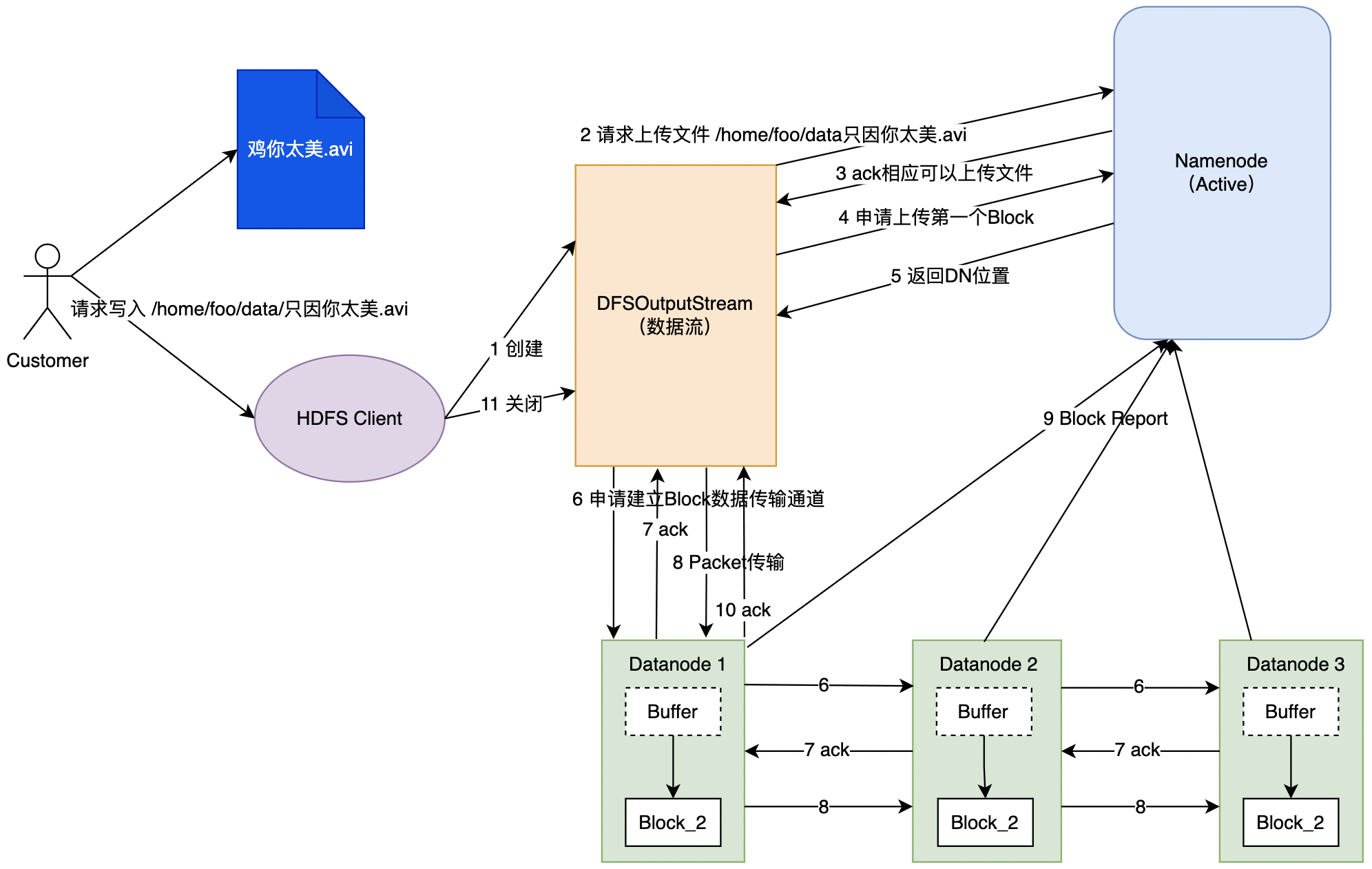
HDFS Client收到用户读请求后,会创建一个数据流对象进行具体的数据写入流程;- 数据流对象向
NN请求上传文件,NN会先检查目标文件的父目录以及目标文件是否存在; NN返回是否可以上传;- 数据流对象请求
NN上传第一个Block; NN返回数据写入的数据块信息;- 数据流对象申请与
DD建立数据传输通道,DD按照网络具体逐级申请建立数据pipeline; - 应答
- 数据流对象收到
NN返回后,开始具体的数据写入,客户端的数据会实现缓存在数据流对象中,之后这些数据会被切分成多个数据包(Packet),依次写入数据节点; - 第一个
Block数据传输完了以后,重复4~8,写入后续的Block;
- 多个
DN可以并行写- 若一个
DN阻塞,则整体写入流程会阻塞;- 文件都是追加写,不是随机写;
4.3 Datanode 启动流程
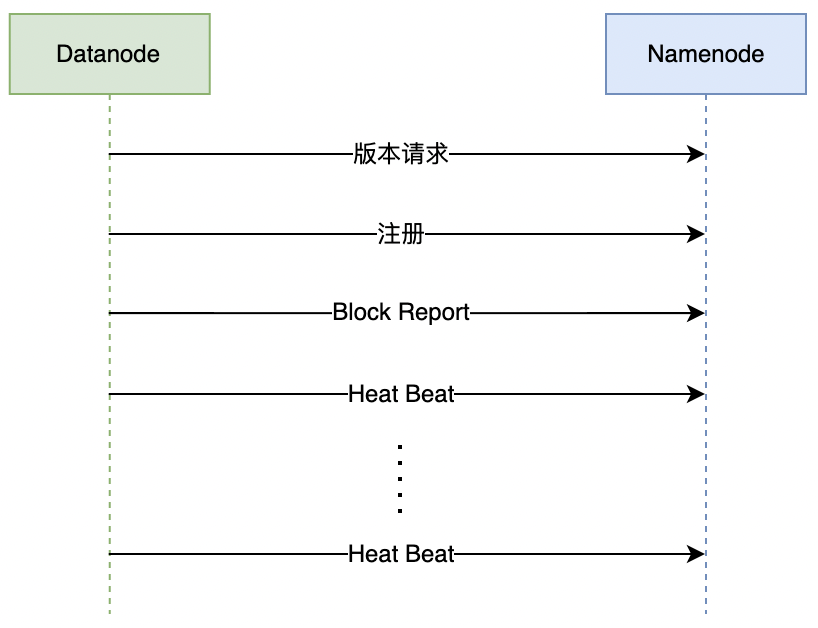
DN 启动后会 NN 进行交互,主要包括三个部分:
- 握手;
- 注册;
- 数据块以及缓存汇报;
DN启动时,先会请求NN的版本号以及存储信息等,确认NN的版本号是否与DN当前的版本是否一致;DN与NN成功握手后,DN会向NN申请节点注册,NN收到请求,判断DN是否属于集群,并检查版本号是否一致;- 注册成功后,
DN需要将本地存储的所有数据块和已经缓存的数据块上报给NN,NN根据这些信息在内存中建立数据库与DN之间的映射关系;- 完成以上所有步骤,
DN完成启动。后续需要定期向NN发送心跳,NN根据心跳判断DN的状态并决定DN是否能够对外提供服务。同时DN与NN之间的交互信息都是通过心跳来携带传输。
4.5 HA 切换流程
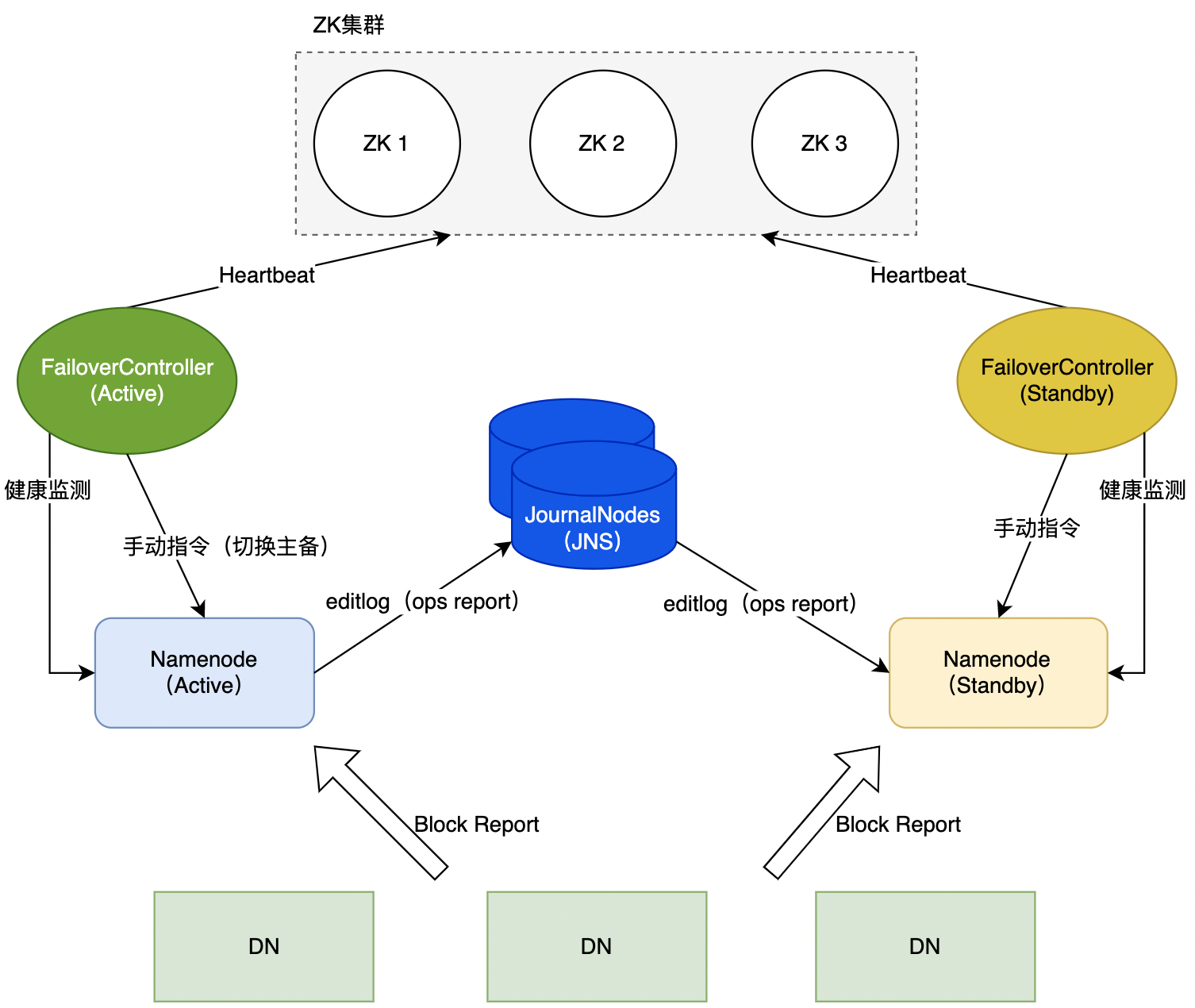
HDFS 的高可用(High Availability,HA)是解决 NN 可能出现单点故障的问题。在 HA 的 HDFS 集群中,同时运行两个 NN(Active、Standby),其中 Active NN 与 Standby NN 的状态要求实时同步,即:要求两个 NN 的命名空间(Namespace)一致并且 Block 与 DN 之间的映射关系也一致。
- 为了保证
Namespace的一致性,两个NN需要与一组独立运行的节点(JournalNodes,JNS)通信,Active NN定期将namespace的操作记录在editlog,并写入JNS多数节点中。Standby NN监听JNS,如果返现JNS的editlog有更新,会进行同步更新与当前的命名空间合并。 - 对于
Block与DN映射关系的一致性,要求HDFS中所有的DN同时向Active NN和Standby NN发送Heatbeat以及Block Report。
通过 ZK 的 FailoverController 实时监控 HA 的状态(NN 状态,系统运行状态、硬件状态等),当 Active NN 处于不可服务状态时,FailoverController 则会自动触发主备切换。此外 HDFS 还支持手动切换主备(DFSHAAdmin)。
5 总结