布隆过滤器详解
1 什么是布隆过滤器
布隆过滤器 (BloomFilter) 是 1970 布隆(Burton Howard Bloom )提出的,它是一种节省空间(space efficient)的概率性数据结构,为一个很长的二进制向量,主要用于判断一个元素是否在一个集合中。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。理论情况下添加到集合中的元素越多,误报的可能性就越大。并且,存放在布隆过滤器的数据不容易删除。
在程序的世界中,布隆过滤器是程序员的一把利器,利用它可以快速地解决项目中一些比较棘手的问题。如网页 URL 去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题。
几个概念
缓存雪崩
当某一个时刻出现大规模的缓存失效的情况,那么就会导致大量的请求直接打在数据库上面,导致数据库压力巨大,如果在高并发的情况下,可能瞬间就会导致数据库宕机。这时候如果运维马上又重启数据库,马上又会有新的流量把数据库打死。这就是缓存雪崩。
缓存击穿
其实跟缓存雪崩有点类似,缓存雪崩是大规模的 key 失效,而缓存击穿是一个热点的 Key,有大并发集中对其进行访问,突然间这个 Key 失效了,导致大并发全部打在数据库上,导致数据库压力剧增。这种现象就叫做缓存击穿。
缓存穿透
我们使用 Redis 大部分情况都是通过 Key 查询对应的值,假如发送的请求传进来的 key 是不存在 Redis 中的,那么就查不到缓存,查不到缓存就会去数据库查询。假如有大量这样的请求,这些请求像 “穿透” 了缓存一样直接打在数据库上,这种现象就叫做缓存穿透。
2 基本原理
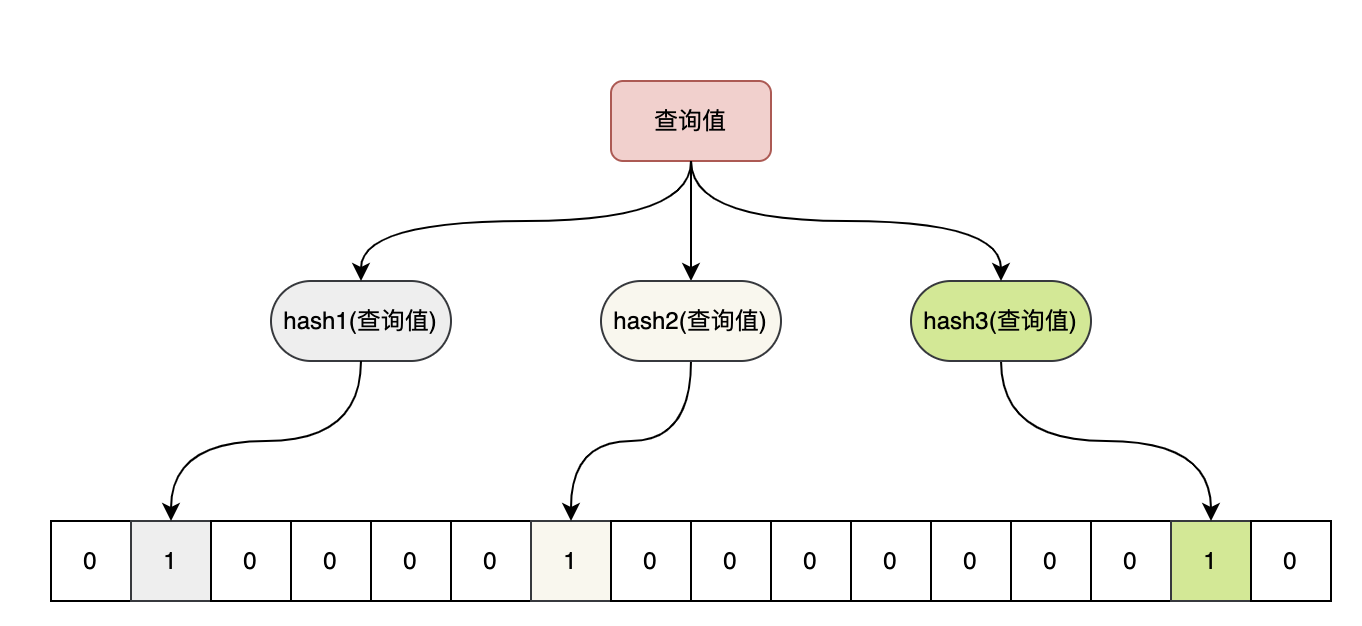
当一个元素加入布隆过滤器中的时候,会进行如下操作:
- 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
- 根据得到的哈希值,在位数组中把对应下标的值置为 1。
对一个值进行查询时:
- 对待查询值再次进行相同的哈希计算;
- 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值可能在布隆过滤器中,如果存在一个值不为 1,说明该元素一定不在布隆过滤器中。
因为对于不同的字符串可能得到相同的 hash 值,所以存在概率性的误报。此种情况可以通过增加数组的大小或者调整更好的 hash 函数来提高过滤器的准确率。
如图:位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000Bit / 8 = 125000 Byte = 125000/1024 kb ≈ 122kb 的空间。
3 代码实现
手动 java 实现
通过以上介绍可知,布隆过滤器需要具备以下特性:
- 一个合适大小的位数组保存数据;
- 几个不同的 hash 函数;
- 添加元素到位数组的方法实践;
- 判断元素是否存在于位数组的方法实践;
1 | import java.util.BitSet; |
测试结果
1 | false |
Google 开源 Guava 实现
日常项目中可以使用 Guava 实现的过滤器布隆过滤器
依赖
1 | <dependency> |
使用
1 | // 创建布隆过滤器对象 |
当 mightContain() 方法返回 true 时,我们可以 99%确定该元素在过滤器中,当过滤器返回 false 时,我们可以 100%确定该元素不存在于过滤器中。
缺陷:
只能单机使用(另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了
Redis 中的过滤器
TODO
4 使用场景
- 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5 亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等;
- 去重:比如爬给定网址的时候对已经爬取过的 URL 去重;
- spark 的 jion 操作中
Runtime Filter的过滤原理实现; - 反垃圾邮件,从数十亿个垃圾邮件列表中判断某邮箱是否垃圾邮箱(同理,垃圾短信);
5 后续探讨
扩容
因为布隆过滤器的不可逆,我们没法重新建一个更大的布隆过滤器然后去把数据重新导入。可以采取的扩容的方法是,保留原有的布隆过滤器,建立一个更大的,新增数据都放在新的布隆过滤器中,去重的时候检查所有的布隆过滤器。用一个新的布隆过滤器和多个老的布隆过滤器共同组成一个新的过滤器,提供相同的接口。
删除值
由于判断某个元素在 bloom filter 是否存在是个概率问题,所以导致布隆过滤器不容易删除一个值。可以通过布隆过滤器的变体 CBF (Counting BloomFilter) 来解决。
CBF 将标准 Bloom Filter 位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的 k(k 为哈希函数个数)个 Counter 的值分别加 1,删除元素时给对应的 k 个 Counter 的值分别减 1。Counting Bloom Filter 通过多占用几倍的存储空间的代价,给 Bloom Filter 增加了删除操作。