分布式系统:CAP 理论
1 引言
分布式系统(Distributed System)已经变得非常常见和重要,现在市面上的大型网站与一些重要的系统几乎都是分布式的。
分布式系统最大的难点就是各个节点的状态如何同步。CAP 理论就是这方面的基本定理,也是理解分布式的起点。
2000年7月,加州大学伯克利分校的Eric Brewer教授在ACM PODC会议上提出CAP猜想。两年后,麻省理工学院的Seth Gilbert和Nancy Lynch从理论上证明了CAP。之后,CAP理论正式成为分布式计算领域的公认定理。
2 定义
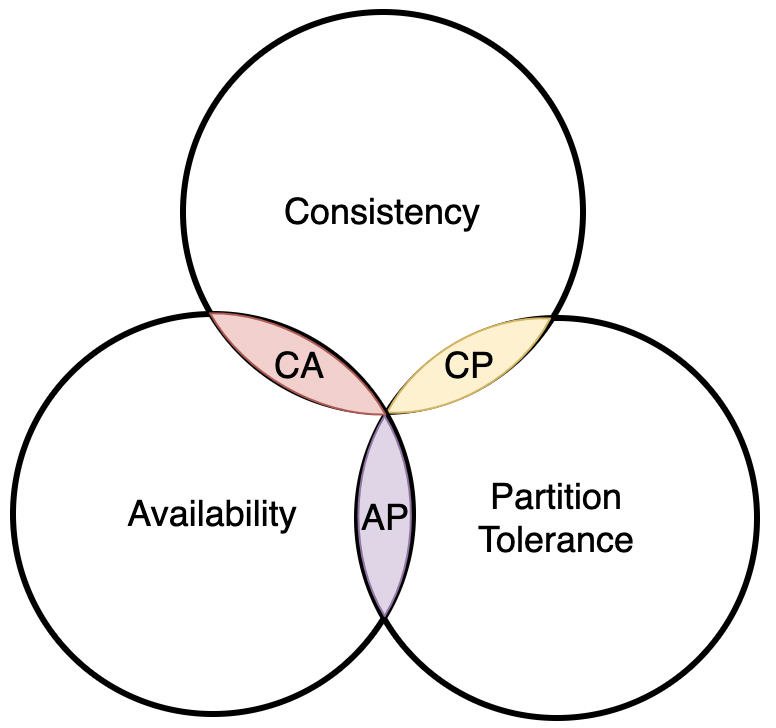
CAP 分别代表分布式系统的三个指标:
C(Consistency,一致性)A(Availability,可用性)P(Partition tolerance,分区容错)
CAP 理论指出:我们无法设计出一种同时满足 CAP 三个指标的分布式协议:
- 该种协议下的副本始终是强一致性的;
- 系统的服务是始终可用的;
- 协议可以容忍任何网络分区异常;
2.1 Consistency 一致性
All nodes see the same data at the same time 对于分布式系统来说,更新操作成功并返回客户端完成后,所有节点在同一时间的数据完全一致。
举例说明
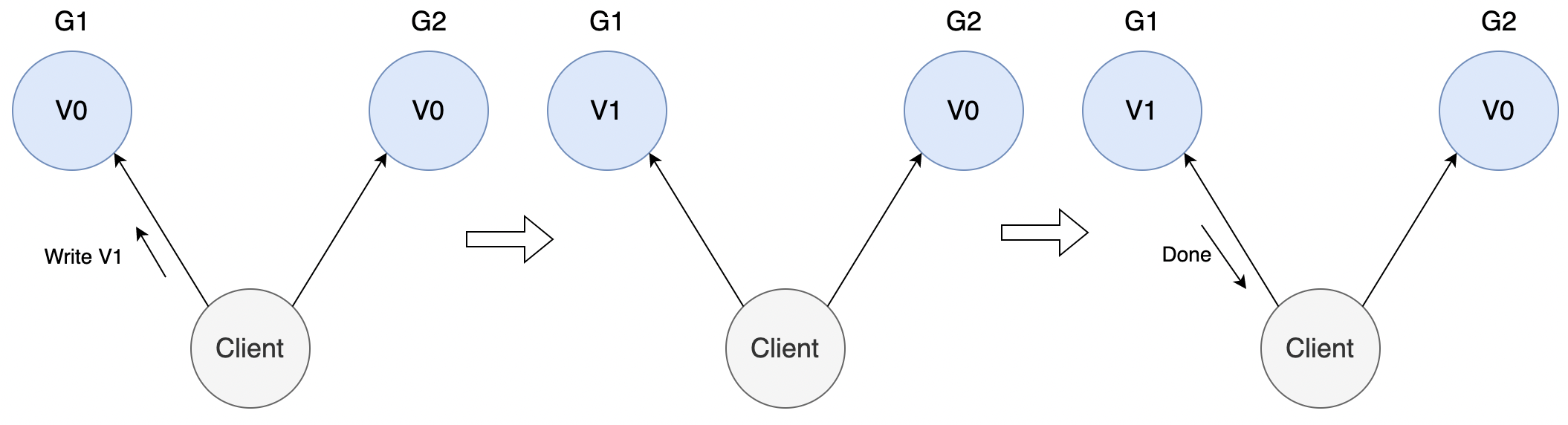
假设系统中某条记录为 V0,客户端向 G1 发起写操作,将其改为 V1,
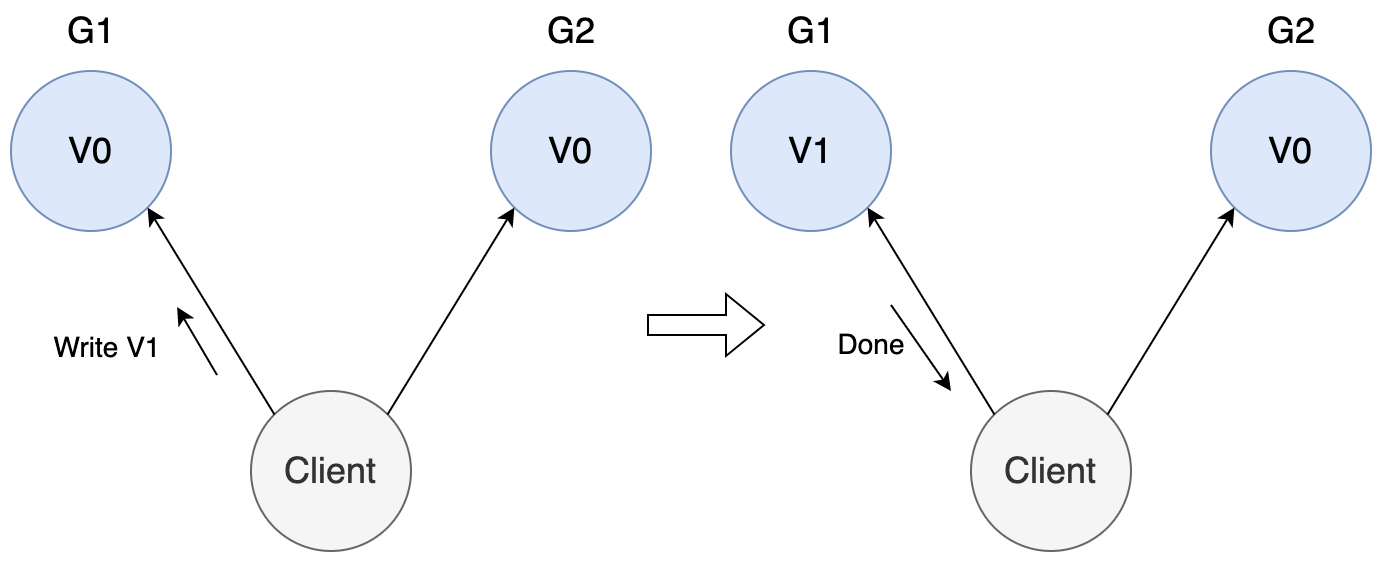
存在的问题:
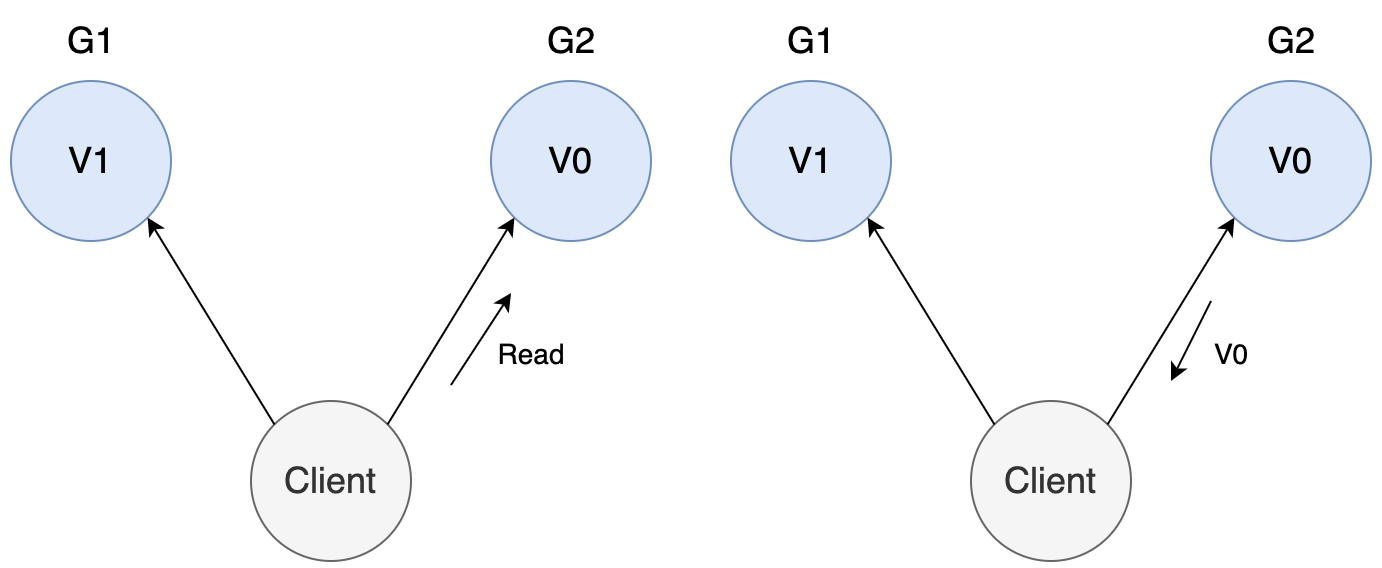
客户端可能向 G2 发起读操作,由于 G2 的值没有同步,因此返回的值为 V0,G1 和 G2 读操作的结果不一致,不满足一致性。
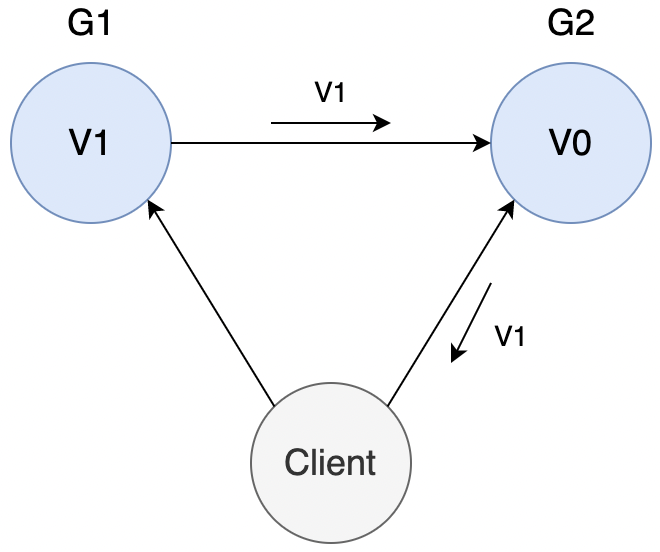
为了保证一致性,即 G2 的值也能变为 V1,则需在 G1 写操作的时候,将信息同步给 G2。
2.2 Availability 可用性
Reads and writes always succeed 系统服务一直可用,且系统的响应在正常时间范围内。
对于一个可用性的分布式系统,每一个非故障节点必须对每个请求做出响应,一般是通过停机时间来衡量一个系统的可用性。
| 可用性分类 | 可用水平(%) | 可容忍停机时间(年) |
|---|---|---|
| 容错可用性 | 99.9999 | < 1 min |
| 极高可用性 | 99.999 | < 5 min |
| 具有故障自动恢复能力的可用性 | 99.99 | < 53 min |
| 高可用性 | 99.9 | < 8.8 h |
| 商品可用性 | 99 | < 87.6 h (3.65d) |
具体的计算方式:
假设淘宝系统的可用性为
5个9,即可用水平为99.999%,则全年可容忍停机时间为:(1 - 0.99999) * 365 * 24 * 60 = 5.256 min
举例说明
用户可以选择向 G1 或者 G2 发起读请求,无论系统的哪个节点,只要收到请求,就必须响应用户,否则不满足可用性。
2.3 Partition Tolerance 分区容错
The system continues to operate despite arbitrary message loss or failure of part of the system 分布式系统在遇到某个节点或者网络分区故障时,仍然能够对外提供满足一致性和可用性的服务。
举例说明
大多数分布式系统都分布在多个子网络,每个子网络都成为一个区(partition),分区容错为区间通信可能失败。假设系统的一台服务器在中国,另外一台服务器在美国,这就是两个分区,且网络通信可能异常。
3 证明
本节证明分布式系统无法同时满足 CAP。
如下图,假设存在一个系统,满足 CAP,即:一致性(Consistency)、可用性(Availability)、分区容错性(Partition Tolarance)
此时系统出现网络分区,同时客户端向系统的 G1 写入 V1,但是 G1 无法将 V1 同步给 G2(正在网络分区)。
此时客户端向 G2 发起读请求,由于系统满足 CAP,所以 G2 必须响应请求(可用性),此时 G2 返回的值为 V0。
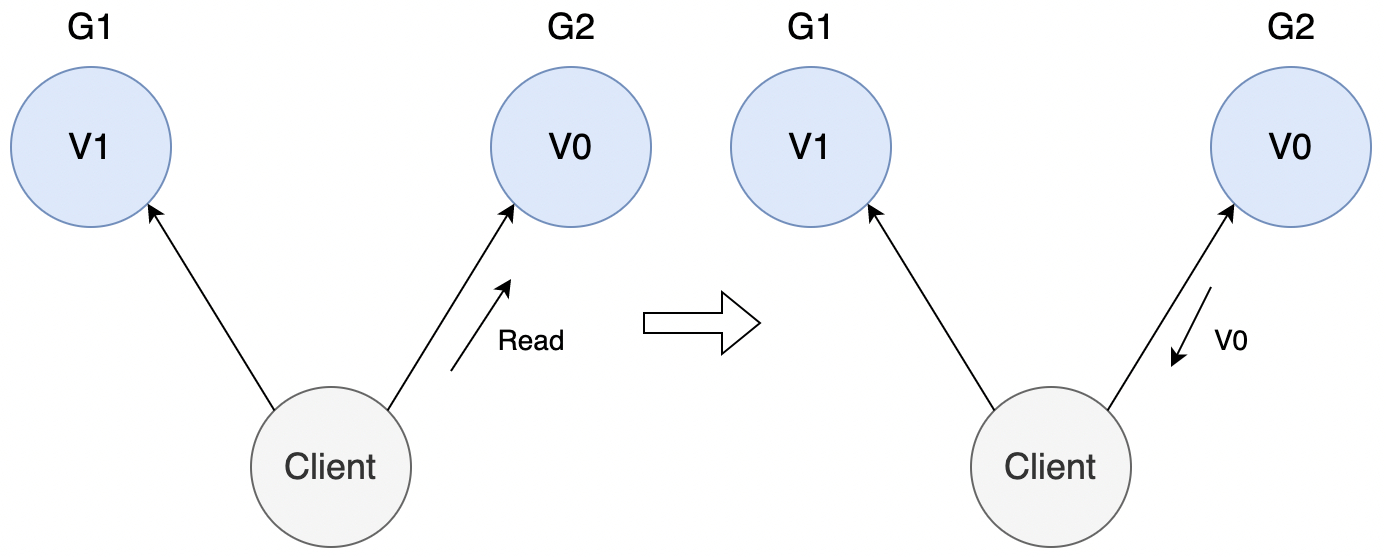
这违反了 CAP 的一致性,与假设相违背。所以无法设计出一个系统同时满足 CAP 理论。
4 权衡
4.1 CA without P
网络分区问题是客观存在的事实,因此分区容错是无法避免的,所以在分布式系统的设计中,要时刻考虑 Partition Tolerance 的情况,只能在 CA 之间做权衡。
4.2 CP without A
如果一个分布式系统不要求强的可用性,即容许系统停机或者长时间无响应的话,就可以在 CAP 三者中保障 CP 而舍弃 A。
一个保证了 CP 而一个舍弃了 A 的分布式系统,一旦发生网络故障或者消息丢失等情况,就要牺牲用户的体验,等待所有数据全部一致了之后再让用户访问系统。
设计成 CP 的系统其实也不少,其中最典型的就是很多分布式数据库,他们都是设计成 CP。在发生极端情况时,优先保证数据的强一致性,代价就是舍弃系统的可用性。如 Redis、HBase 等,还有分布式系统中常用的 Zookeeper 也是在 CAP 三者之中选择优先保证 CP 的。
比如
Zookeeper:
ZooKeeper是个CP(一致性 + 分区容错性)的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性。但是它不能保证每次服务请求的可用性,也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果。ZooKeeper是分布式协调服务,它的职责是保证数据在其管辖下的所有服务之间保持同步、一致。所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性的了。
4.3 AP without C
要高可用并允许分区,则需放弃一致性。一旦网络问题发生,节点之间可能会失去联系。为了保证高可用,需要在用户访问时可以马上得到返回,则每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。
这种舍弃强一致性而保证系统的分区容错性和可用性的场景和案例非常多。前面我们介绍可用性的时候说到过,很多系统在可用性方面会做很多事情来保证系统的全年可用性可以达到 N个9,所以,对于很多业务系统来说,比如淘宝的购物,12306 的买票。都是在可用性和一致性之间舍弃了一致性而选择可用性。
比如
12306系统:在 12306 买票的时候肯定遇到过这种场景,当你购买的时候提示你是有票的(但是可能实际已经没票了),你也正常的去输入验证码,下单了。但是过了一会系统提示你下单失败,余票不足。这其实就是先在可用性方面保证系统可以正常的服务,然后在数据的一致性方面做了些牺牲,会影响一些用户体验,但是也不至于造成用户流程的严重阻塞。
需要注意的是,此处说的舍弃了一致性,只是舍弃了强一致性,而选择了最终一致性。在 12306 售票系统中,虽然下单的瞬间可能存在余票不一致的情况,但是最终付款的时候,是保证了最终一致性的。
5 总结
CAP 理论证明了分布式系统无法同时满足:一致性(C,Consistency)、可用性(Availability,A)、分区容错性(Partition Tolerance)的条件。网络分区问题是客观存在的无法避免,系统设计需要在 CA 之间 tradeoff,可以根据具体的业务场景来考虑。