Google Protobuf 详解
1 简介
Protobuf 是由 Google 设计的一种高效、轻量级的信息描述格式,起初是在 Google 内部使用,后面开源,它具有语言中立、平台中立、高效、可扩展等特性,它非常适合用来做数据存储、RPC 数据交换等。与 json、xml 相比, Protobuf 的编码长度更短、传输效率更高,其实严格意义上讲,json、xml、并非是一种「编码」,而只能称之为「格式」,json、xml 的内容本身都是字符形式,它们的编码采用的是 ASCII 编码。
| - | xml | json | protobuf |
|---|---|---|---|
| 数据结构 | 结构一般复杂 | 结构简单 | 结构比较复杂 |
| 数据存储方式 | 文本 | 文本 | 二进制 |
| 数据存储大小 | 大 | 一般 | 小 |
| 解析效率 | 慢 | 一般 | 快 |
| 跨语言支持 | 非常多 | 多 | 一般 |
| 开发成本 | 比较繁琐 | 非常简单 | 一般 |
| 学习成本 | 一般 | 低 | 一般 |
一旦定义了要处理的数据的数据结构之后,就可以利用 Protobuf 的代码生成工具生成相关的代码。只需使用 Protobuf 对数据结构进行一次描述,即可利用各种不同语言 (proto3 支持 C++、Java、Python、Go、Ruby、Objective-C、C#) 或从各种不同流中对你的结构化数据轻松读写。
本文讲述 Protobuf 的底层编码原理,以便于了解 Protobuf 为什么编码长度短并且扩展性强,与此同时我们也将了解到它有哪些不足?
2 用法
2.1 关于版本
Protobuf 有两个大版本,proto2 和 proto3,同比于 python2.x 和 python3.x 版本。初学者建议直接学习 proto3 版本。
proto3 相对于 proto2 而言,简而言之是支持了更多的语言(Ruby、C#等)、删除了一些复杂的语法和特性、引入了更多的约定等。
与 json 开箱即用不一样的是,protobuf 需要依赖于工具包编译成
java文件或者go文件等,所以需要关注 protobuf 的版本
2.2 使用
2.2.1 安装
使用 proto 之前需要先安装编译器,官方下载地址,具体安装步骤可自行搜索。可在控制台使用以下命令检查是否安装成功:
mark.hct@ ~ % protoc –version
libprotoc 3.21.12
也可以通过在 ideal 安装 Protobuf Support,之后通过 maven 来编译 proto 文件
2.2.2 proto 文件
在 proto 文件中,需要定义程序中需要处理的结构化数据。其中结构化数据被称为 Message。proto 文件非常类似于 java 中的 bean。
proto文件对应序列化理论中的IDL(Interface description language)接口描述语言
定义一个 Test.proto 文件
1 | syntax = "proto3"; // PB协议版本 |
message 语法说明(部分)
1、 proto3 中,枚举的第一个常量名的编号必须为 0;
由于 proto3 的默认值规则进行了调整,枚举的默认值为第一个,所以必须将第一个常量的标号设置为 0,但是这和业务有时是冲突的,此时,将第一个常量设置为
xx_UNSPECIFIED=0,如:ENUM_TYPE_UNSPECIFIED = 0
2、同一个 proto 文件中,多个枚举之间不允许定义相同的常量名
1 | enum IDE1 { |
此时会报错,IDEA is already defined in "xxx"
3、 Any 理解
google.protobuf.Any 可以理解为 java 中的 object,但又和 object 不同。Any 不是所有的 Message 的父类,而 object 是所有类的父类。如以下示例代码:
Java Api 的代码为:
1 |
|
对应的 proto 定义为:
1 | message ApiResult { |
protobuf 提供了更多选项和数据类型,本文不做详细介绍,感兴趣可以参考这里
2.2.3 编译
从控制台进入 proto 文件所在路径,通过 protoc 进行编译得到对应的 java 文件拷贝到项目中使用。
1 | protoc -I=$path --java_out=$path $path/$file |
参数说明:
- -I /-proto_path:指定.proto 文件所在的路径
- –java_out:编译成 java 文件时,标明输出目标路径
- $path/$file:指定需要编译的.proto 文件
2.2.4 项目使用
对于
protoc编译生成的java代码实现序列化和反序列化,需要在工程中添加protobuf-java的依赖1
2
3
4
5<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.21.12</version>
</dependency>可以使用多种方式进行序列化和反序列化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import test.PersonTestProtos.PersonTest.PhoneNumber.PhoneType;
import test.PersonTestProtos.PersonTest.Sex;
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
/**
* @author mark.hct
* @version ProtoTest.java v 0.1 2023/1/15 21:53 Exp $
* @description
*/
public class ProtoTest {
public static void main(String[] args) {
try {
/** Step1:生成 personTest 对象 */
PersonTestProtos.PersonTest.Builder personBuilder = PersonTestProtos.PersonTest.newBuilder();
// personTest 赋值
personBuilder.setName("cxk");
personBuilder.setEmail("cxk@gmail.com");
personBuilder.setSex(Sex.MALE);
// 内部的 PhoneNumber 构造器
PersonTestProtos.PersonTest.PhoneNumber.Builder phoneNumberBuilder = PersonTestProtos.PersonTest.PhoneNumber.newBuilder();
// PhoneNumber 赋值
phoneNumberBuilder.setType(PhoneType.MOBILE);
phoneNumberBuilder.setNumber("138xxxx");
// personTest 设置 PhoneNumber
personBuilder.addPhone(phoneNumberBuilder);
// 生成 personTest 对象
PersonTestProtos.PersonTest personTest = personBuilder.build();
/** Step2:序列化和反序列化 */
// 方式一 byte[]:
// 序列化
byte[] bytes = personTest.toByteArray();
PersonTestProtos.PersonTest personTestResult1 = PersonTestProtos.PersonTest.parseFrom(bytes);
System.out.printf("反序列化得到的信息,姓名:%s,性别:%d,手机号:%s%n", personTestResult1.getName(), personTest.getSexValue(),
personTest.getPhone(0).getNumber());
// 方式二 ByteString:
// 序列化
ByteString byteString = personTest.toByteString();
System.out.println(byteString.toString());
// 反序列化
PersonTestProtos.PersonTest personTestResult2 = PersonTestProtos.PersonTest.parseFrom(byteString);
System.out.printf("反序列化得到的信息,姓名:%s,性别:%d,手机号:%s%n", personTestResult2.getName(), personTest.getSexValue(),
personTest.getPhone(0).getNumber());
// 方式三 InputStream
// 粘包,将一个或者多个protobuf 对象字节写入 stream
// 序列化
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
personTest.writeDelimitedTo(byteArrayOutputStream);
// 反序列化,从 steam 中读取一个或者多个 protobuf 字节对象
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(byteArrayOutputStream.toByteArray());
PersonTestProtos.PersonTest personTestResult3 = PersonTestProtos.PersonTest.parseDelimitedFrom(byteArrayInputStream);
System.out.printf("反序列化得到的信息,姓名:%s,性别:%d,手机号:%s%n", personTestResult3.getName(), personTest.getSexValue(),
personTest.getPhone(0).getNumber());
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
3 原理
3.1 protobuf 数据结构
1、采用 TLV 存储方式,即 Tag-Length-Value(标识 - 长度 - 字段值);
2、不需要分隔符就能分开字段,较少了分隔符的使用;
3、各字段存储得非常紧凑,存储空间利用率非常高;
4、若字段没有被设置字段值,那么该字段在序列化时的数据是完全不存在的,即不需要要编码;
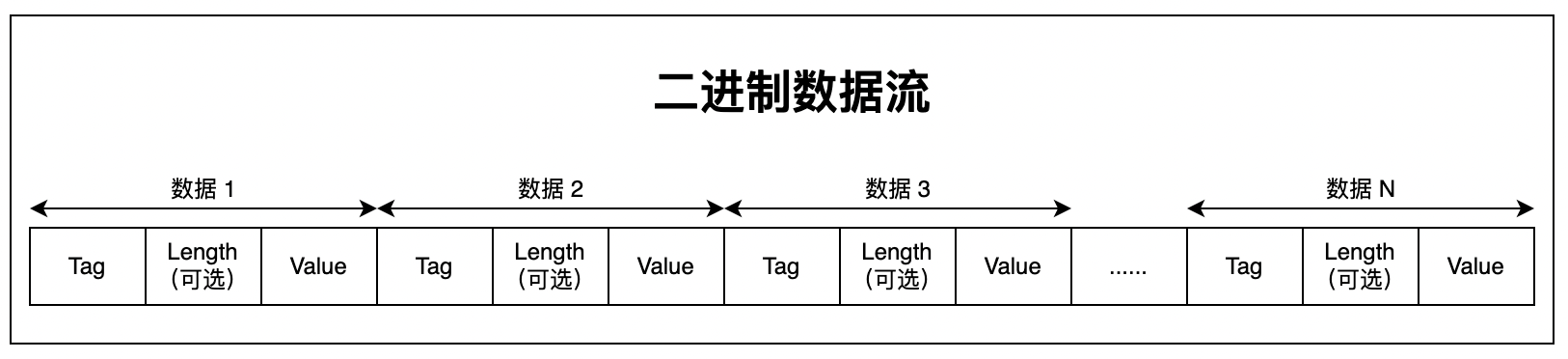
- Tag:字段标识号,用户表示字段;
- Length:Value 的字段长度;
- Value:消息字段经过编码后的值;
3.2 protobuf 数据组织
首先来看一个例子,假设客户端和服务端使用 protobuf 作为数据交换格式,proto 的具体定义为:
1 | syntax = "proto3"; |
Request 中包含了一个名称为 age 的字段,客户端和服务端双方都用同一份相同的 proto 文件是没有任何问题的,假设客户端自己将 proto 文件做了修改,修改后的 proto 文件如下:
1 | syntax = "proto3"; |
在这种情形下,服务端不修改应用程序仍能够正确地解码,原因在于序列化后的 Protobuf 没有使用字段名称,而仅仅采用了字段编号,与 json xml 等相比,protobuf 不是一种完全自描述的协议格式,即接收端在没有 proto 文件定义的前提下是无法解码一个 protobuf 消息体。与此相对的,json xml 等协议格式是完全自描述的,拿到了 json 消息体,便可以知道这段消息体中有哪些字段,每个字段的值分别是什么,其实对于客户端和服务端通信双方来说,约定好了消息格式之后完全没有必要在每一条消息中都携带字段名称,protobuf 在通信数据中移除字段名称,这可以大大降低消息的长度,提高通信效率。对于不同数据类型采用不同的序列化方式(编码方式 & 数据存储方式)如下表:
| wire_type | 编码方式 | 编码长度 | 存储方式 | 代表的数据类型 |
|---|---|---|---|---|
| 0 | Vaint(负数时以 Zigzag 辅助编码) | 变长 (1-10 个字节) | T - V | int32, int64, unit32, unit64, bool, enum, sint32, sint64 (负数时使用) |
| 1 | 64-bit | 固定 8 个字节 | T - V | fixed64, sfixed64, double |
| 2 | Length-delimi | 变长 | T - L - V | string, bytes, embedded messages, packed repeated fields |
| 3 | Start group | 已弃用 | 已弃用 | Groups(已弃用) |
| 4 | End group | 已弃用 | 已弃用 | Groups(已弃用) |
| 5 | 32-bit | 固定 4 个字节 | T - V | Fixed32, sfixed32, float |
对于 int32, int64, uint32 等数据类型在序列化之后都会转为 Varint 编码,除去两种已标记为已废弃(deprecated) 的类型,目前 Protobuf 在序列化之后的消息类型 (wire_type) 总共有 4 种,Protobuf 除了存储字段的值之外,还存储了字段的编号以及字段在通信线路上的格式类型 (wire-type), 具体的存储方式为:
field_number << 3 | wire_type
即将字段标号逻辑左移 3 位,然后与该字段的 wire type 的编号按位或,在上表中可以看到,wire type 总共有 6 种类型,因此可以用 3 位二进制来标识,所以低 3 位实际上存储了其后所跟的数据的 wire type,接收端可以利用这些信息,结合 proto 文件来解码消息结构体。
以上面 proto 为例来看一段 Protobuf 实际序列化之后的完整二进制数据,假设 age 为 5,由于 age 在 proto 文件中定义的是 int32 类型,因此序列化之后它的 wire_type 为 0,其字段编号为 1,因此按照上面的计算方式,即 1 << 3 | 0,所以其类型和字段编号的信息只占 1 个字节,即 00001000,后面跟上字段值 5 的 Varint 编码,所以整个结构体序列化之后为(T - V格式):

有了字段编号和 wire type,其后所跟的数据的长度便是确定的,因此 Protobuf 是一种非常紧密的数据组织格式,其不需要特别地加入额外的分隔符来分割一个消息字段,这可大大提升通信的效率,规避冗余的数据传输。
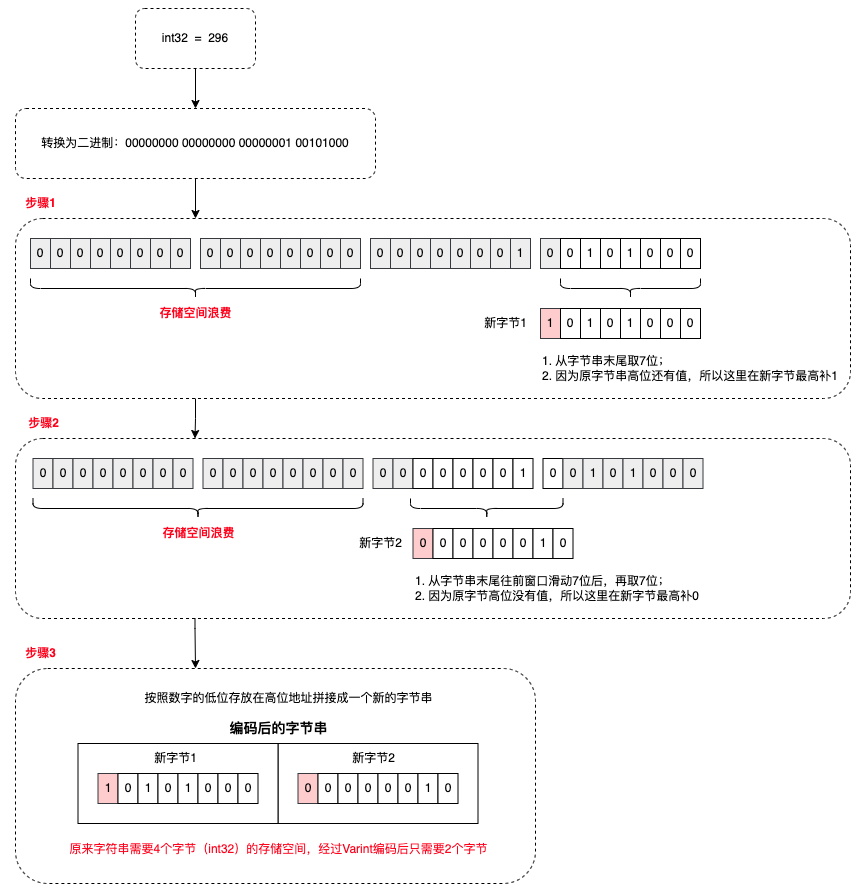
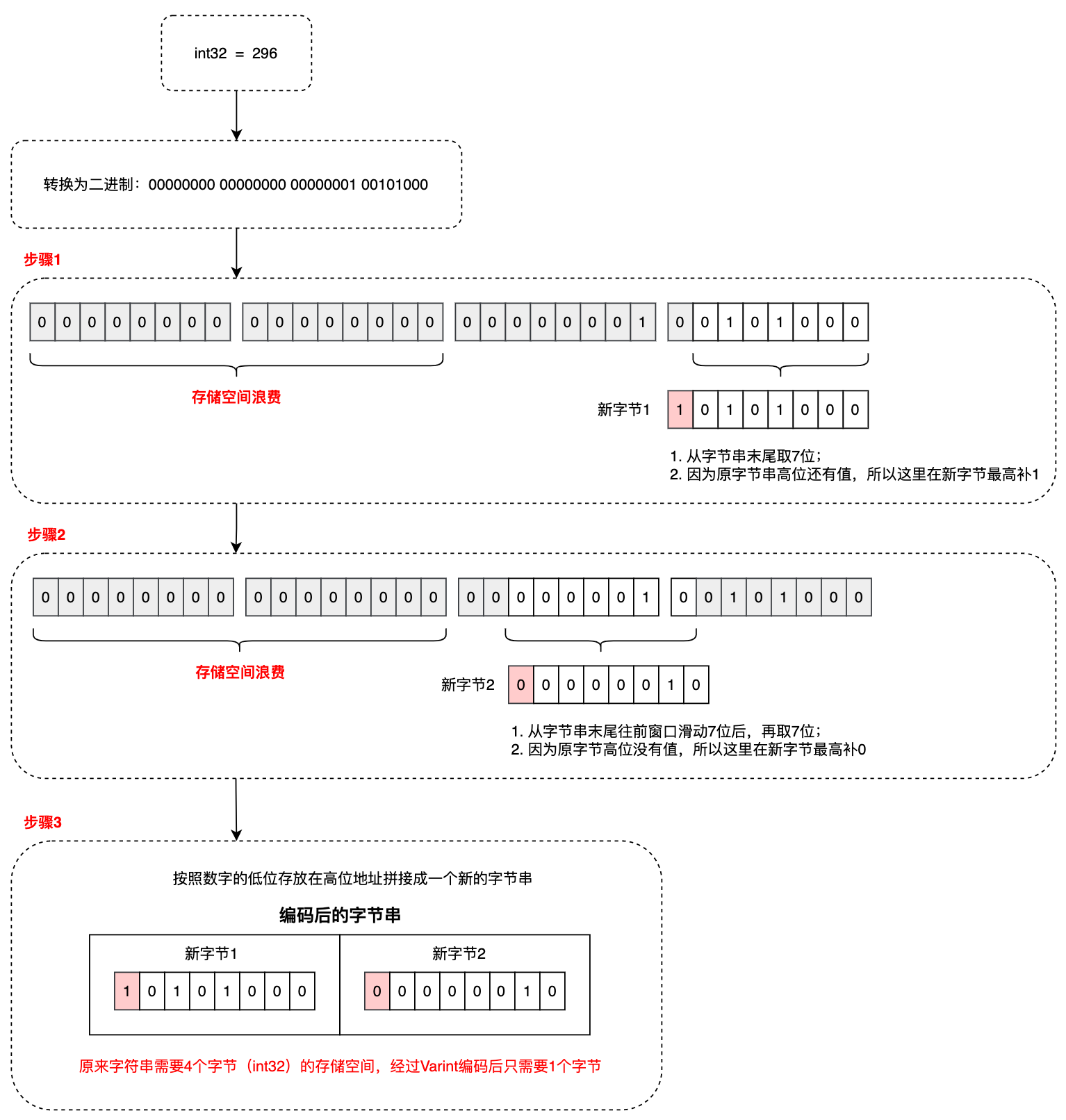
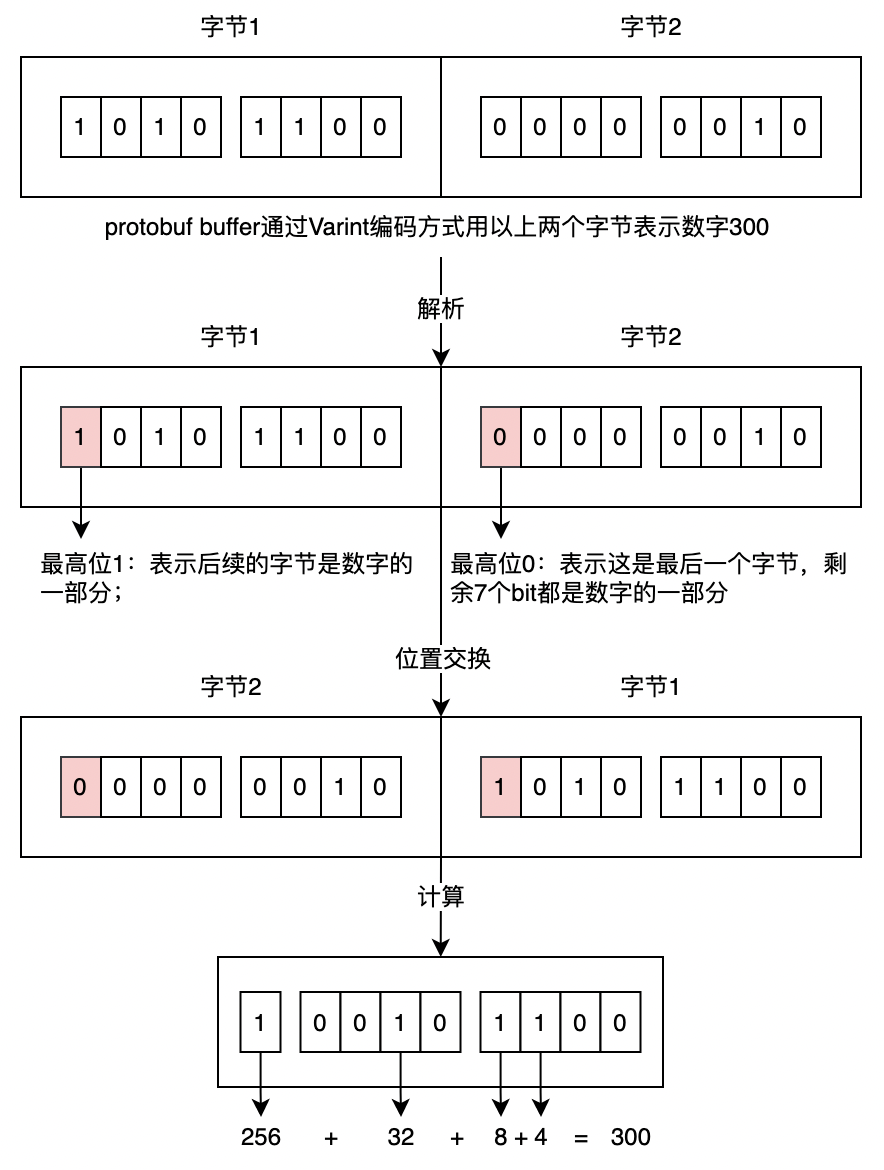
3.3 Varint 编码
普通的 int 数据类型,无论值的大小,所占用的存储空间都是相等的,从这点这出发考虑根据数值大小来动态地占用存储空间,使得值比较小的数字占用较少的字节数,值相对比较大的数字占用比较多的字节数,这就是变长整型编码的基本思想,采用变长整型编码的数字,其占用的字节数不是完全一致的,为了达到这个目的,Varint 编码使用每个字节的最高有效位作为标志位,而剩余的 7 位以二进制补码的形式来存储数字值本身:
- 当最高位有效位为 1 时,代表后面还跟有字节;
- 当最高位有效位为 0 时,代表该数字式最后的一个字节;
在 protobuf 中,使用的 Base128 Varint 编码,之所以叫这个名字原因及时在这种方式中,使用 7 bit 来存储数字,Base128 Varint 采用的是小端序,即数字的低位存放在高位地址。
编码案例 1
编码案例 2
解码案例
3.4 Zigzag 编码
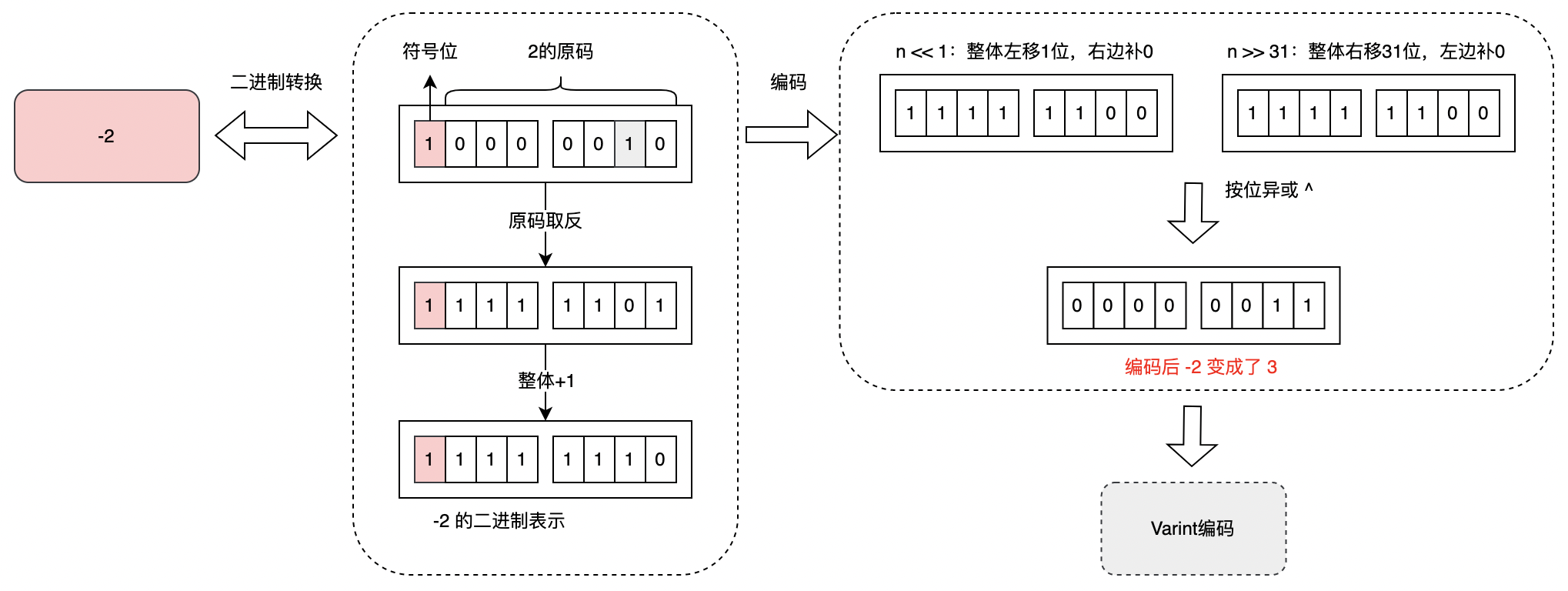
Varint 编码的实质在于去掉数字开头的 0,因此可以缩短数字所占的存储字节数,在上一章节中,说明了整数的 Varint 编码,但是如果数字为负数时,使用 Varint 编码会占用恒定的 10个字节,原因在于负数的符号位 1。对于负数,其从符号位开始的高位均为 1,在 protobuf 的具体实现中,会将此视为一个很大的无符号数。
究其原因在于 protobuf 的内部将 int32 类型的负数转换为 uint64 来处理,转换后的 unit64 数值的高位全是 1,相当于是一个 8 字节的很大的无符号数,因此采用 Base128 Varint 编码后将恒定占用 10 个字节的空间,可见 Varint 编码对于负数时毫无优势,甚至比普通的固定 32 为存储还要多占 4 个字。Varint 编码的实质在于设法移除数字开头为 0 的比特位,由于负数的高位都为 1,因此 Varint 编码在此场景下都会失效,Zigzag 编码便是为了解决这个问题,其大致思想是:首先对负数做一次变换,将其映射成一个正数,变换后便可以使用 Varint 编码进行压缩。这里关键的一点在于变换算法,其算法必须是可逆的,既可以根据变换后的值计算出原始值,否则无法解码,同时要求变换算法尽可能简单,以避免影响 protobuf 编码、解码的性能。
Zigzag 编码的计算方式为:
(n << 1) ^ (n >> 31)
编码案例
3.5 定长编码
double、float 等数据结构的长度是确定的,当解析到这种类型的数据时,直接按照对应长度取数即可。
4 总结
Protobuf是一种高效的数据描述格式,具有平台无关、语言无关、可扩展等特点,适合做数据存储、RPC 的通信协议等场景;Protobuf采用Varint编码和Zigzag编码来编码数据,其中Varint编码的思想是移除数字高位的0,用变长的二进制位来描述一个数字,对于小数字, 其编码长度短,可提高数据传输效率,但由于它在每个字节的最高位额外采用了一个标志位来标记其后是否还跟有有效字节,因此对于大的正数,它会比使用普通的定长格式占用更多的空间,另外对于负数,直接采用Varint编码将恒定占10个字节,Zigzag编码可将负数映射为无符号的正数,然后采用Varint编码进行数据压缩,在各种语言的Protobuf实现中,对于int32类型的数据,Protobuf都会转为uint64而后使用Varint编码来处理,因此当字段可能为负数时,我们应使用sint32或sint64,这样Protobuf会按照Zigzag编码将数据变换后再采用Varint编码进行压缩,从而缩短数据的二进制位数;Protobuf不是完全自描述的信息描述格式,接收端需要有相应的解码器 (即proto定义) 才可解析数据格式,序列化后的Protobuf数据不携带字段名,只使用字段编号来标识一个字段,因此更改proto的字段名不会影响数据解析 (但这显然不是一种好的行为),字段编号会被编码进二进制的消息结构中,因此我们应尽可能地使用小字段编号;Protobuf是一种紧密的消息结构,编码后字段之间没有间隔,每个字段头由两部分组成: 字段编号和wire_type,字段头可确定数据段的长度,因此其字段之前无需加入间隔,也无需引入特定的数据来标记字段末尾,因此Protobuf的编码长度短,传输效率高;